


The release of models like DeepSeek-V3 and DeepSeek-R1 marked an important milestone for large language models (LLM). Suddenly, open-source models were achieving performance startlingly close, and in some benchmarks exceeding, that of leading proprietary giants like GPT-4o, o1, and Claude 3.5 Sonnet—and doing so using just a fraction of the training resources. This wasn’t just an incremental improvement. It signaled that cutting-edge AI wasn’t solely the domain of closed labs.
But how did DeepSeek achieve this remarkable blend of performance and efficiency? It wasn’t one magic bullet, but a series of clever technical innovations across the model architecture, training algorithms, and hardware integration. In a recent paper, researchers at the University of Texas at Dallas and Virginia Tech explore these innovations in detail. Here is a summary of these innovations and some of the key ingredients that made DeepSeek models stand out.
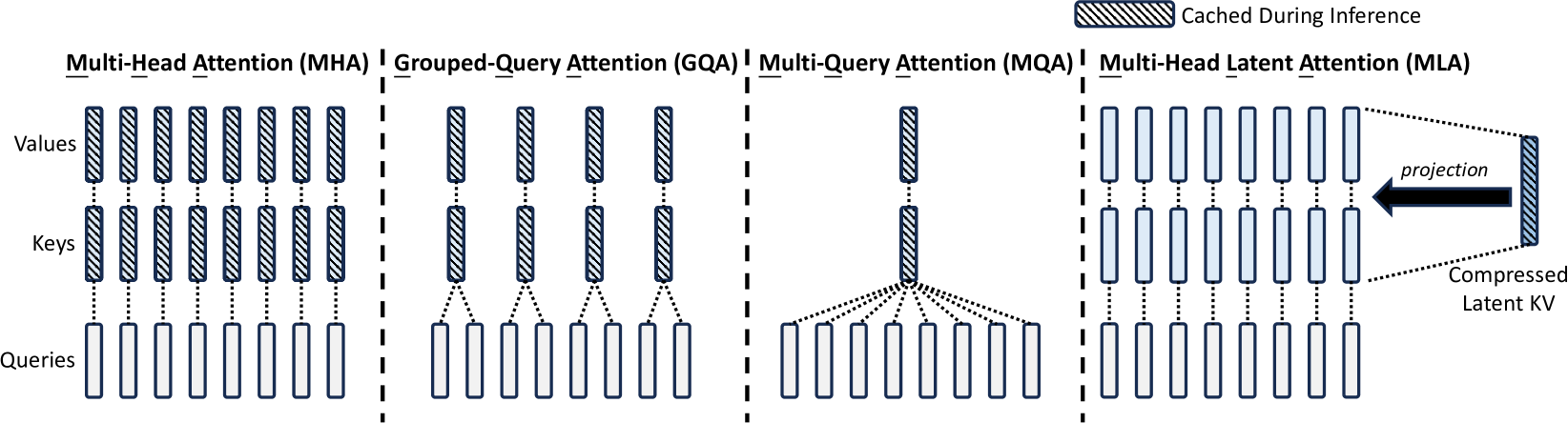
Multi-Head Latent Attention (MLA)
The attention mechanism is the heart of transformers, allowing models to weigh the importance of different words when processing text. However, standard Multi-Head Attention (MHA) has a costly Achilles’ heel: the Key-Value (KV) cache. To speed up generation, models store intermediate calculations (Keys and Values) for previous tokens. But this cache balloons rapidly with longer contexts, demanding huge amounts of memory.
DeepSeek-V2 introduced the idea of Multi-Head Latent Attention (MLA). The core idea is low-rank compression: instead of storing the full, high-dimensional Keys and Values, MLA compresses them into a much smaller “latent” vector. Think of it like keeping concise summary notes instead of full verbatim transcripts—you capture the essence with much less space.
While there are other attention optimization techniques (two other popular techniques are Group-Query Attention and Multi-Query Attention), MLA stands out because it does not sacrifice accuracy for efficiency.
Furthermore, DeepSeek refined the Rotary Position Embedding (RoPE), a technique that encodes token positions when processing the input to the model. Standard RoPE, when combined with MLA’s compression, created efficiency roadblocks during inference. DeepSeek decoupled it: they created a separate, parallel pathway using dedicated vectors just for calculating positional influence via RoPE. This allows the main attention calculation (based on the semantic meaning of tokens) to benefit fully from MLA’s compression efficiency, while still accurately incorporating relative positional information. The result? Significantly reduced memory demands for the KV cache, crucial for handling long contexts efficiently.
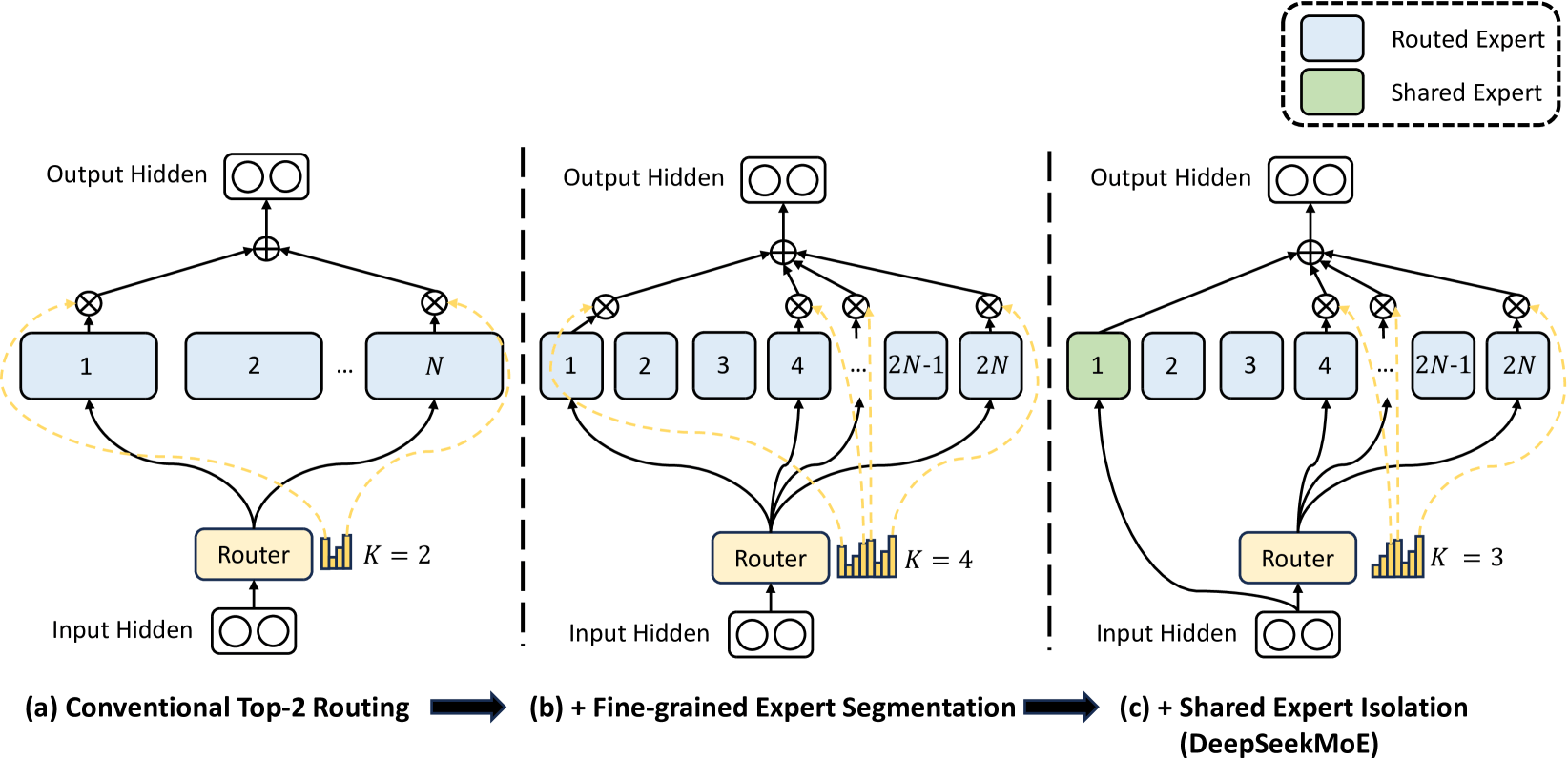
Refining Mixture-of-Experts (MoE) for flexibility and efficiency
Mixture of Experts (MoE) is a technique for scaling LLMs efficiently. Inside each transformer block of classic LLMs (also called dense models), there are a series of large feed-forward neural networks (FFN) that process the values computed by the attention layers. MoEs split these massive FFNs into many smaller “expert” networks, each of which specializes in some tasks. During inference, a “router” activates a subset of the experts based on the computed attention values of the input token. MoEs have proven to be very successful and are used in many popular models, including (reportedly) GPT-4 and Google Gemini models.
But the DeepSeek team further enhanced the standard MoE architecture with two modifications:
Fine-grained expert segmentation: They took the standard experts and chopped them into even smaller, more specialized sub-experts. While the total computation per token remains the same, the router can now select a much more specific combination of these fine-grained experts, boosting the model’s flexibility and ability to handle nuances.
Shared expert isolation: One expert was designated as “shared.” Every token passes through this expert, which learns common knowledge applicable across diverse contexts (e.g., grammar rules or basic reasoning). This reduces redundancy (so routed experts don’t all need to learn the same basics) and frees up the other experts to become even more specialized. (Llama 4 uses a similar architecture.)
To make this complex MoE setup work efficiently on hardware, DeepSeek designed a load-balancing strategy during training to make sure inference was well distributed across different GPUs. Without load balancing, the router might overload a few popular experts on the same GPU while others sit idle, creating bottlenecks. DeepSeek employed strategies, including a clever bias mechanism in DeepSeek-V3, to gently encourage the router to distribute tokens evenly across available experts, ensuring smooth and efficient usage of accelerator hardware.
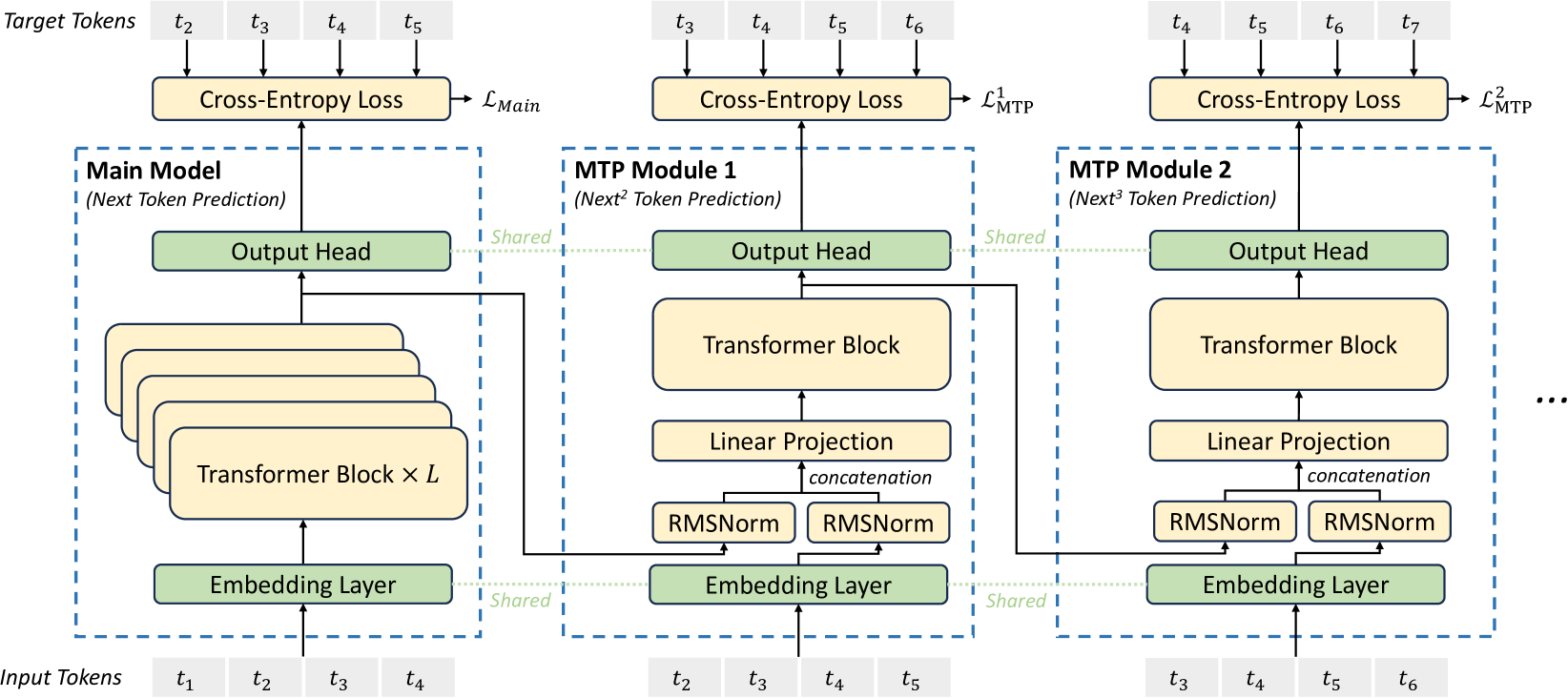
Learning faster with multi-token prediction (MTP)
Traditionally, LLMs learn by predicting one token at a time. DeepSeek-V3 implemented Multi-Token Prediction (MTP) to speed up the training process. At each position, instead of only predicting the next token, the model also predicts the token after that, and potentially several more down the line using parallel prediction heads.
Why? Sample efficiency. It squeezes more learning value out of the same training data. Processing one input token position gives the model multiple learning opportunities (correcting its predictions for token N+1, N+2, N+3, etc.) instead of just one. This helps the model learn faster and potentially achieve better performance from the same dataset size.
However, MTP increases computation overhead during training because you must add extra MTP modules running alongside the main model.
Co-design of algorithms and hardware
DeepSeek emphasized the importance of co-design. This means they didn’t just develop algorithms in isolation. They thought holistically about how the algorithms (like their specific MoE or attention variants), the software frameworks (like custom parallelization libraries), and the physical hardware (like Nvidia GPUs) interact.
They designed an optimized pipeline parallelism strategy to make better use of the accelerators during training and minimize GPU idle time. They also designed an FP8 mixed-precision training technique that uses faster, lower-precision hardware capabilities and slower, high-precision operations intelligently while maintaining accuracy. By optimizing the entire stack together, they significantly enhanced training efficiency, reducing the time and cost required to train their massive models.
According to DeepSeek, they were able to complete the pre-training of the model on 14.8 trillion tokens with 2.788 million H800 GPU hours, which amounts to around $5 million (note that this is not the full cost of training and does not include all the experiments they ran before pre-training and the post-training runs).
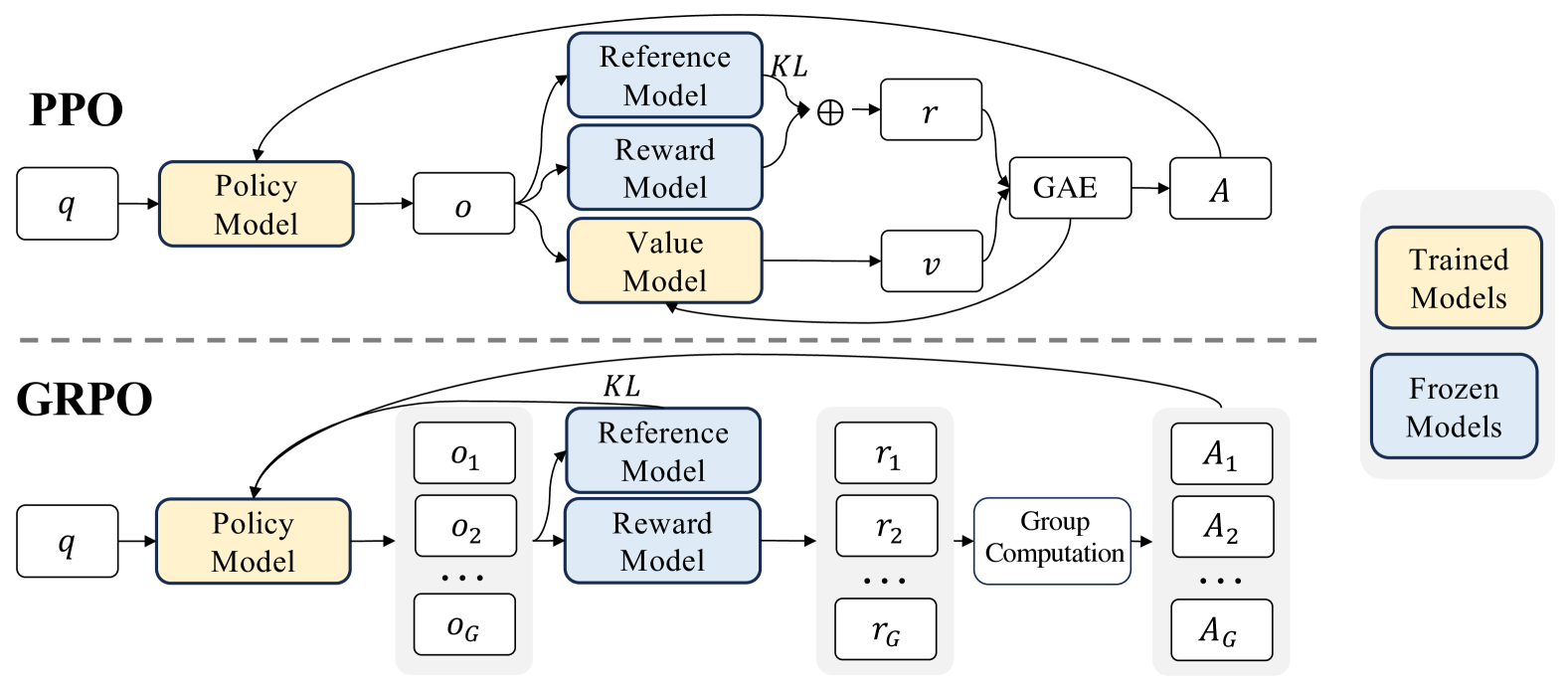
Streamlining RL with Group Relative Policy Optimization (GRPO)
Reinforcement learning (RL) is often used post-training to align LLMs with desired behaviors (helpfulness, safety, instruction following). RL algorithms hinge on an actor (in the case the model) observing states (input tokens), and take actions (generate the answer). A reward model then evaluates the response based on how aligned it is with the desired behavior (for example, the reward model might be trained on users like/dislike behavior to model responses).
A popular algorithm, Proximal Policy Optimization (PPO), typically requires training an auxiliary “Value Model” that estimate expected rewards, which can consume time and resources.
DeepSeek used Group Relative Policy Optimization (GRPO). GRPO cleverly sidesteps the need for a separate value model. It generates a group of potential responses for a given prompt, gets rewards for each, and then evaluates each response relative to the average reward of that specific group. This provides the necessary learning signal without the memory overhead of the value model, simplifying the RL process and making it significantly more memory-efficient.
Pushing the boundaries of post-training
The DeepSeek team discarded the Supervised Fine-Tuning (SFT) step usually used in the post-training stage and went straight to pure reinforcement learning to create DeepSeek-R1-Zero from the base model (DeepSeek-V3-Base). They used GRPO to train the model to elicit complex reasoning behavior without the need for labeled data. Basically, the model was only evaluated based on the outcome (right/wrong) and the format (enclosing its reasoning tokens in <think></think> tags).
This alone got the model very far in developing reasoning abilities, though it had some drawbacks, including poor readability (for example, the model mixed different languages in its reasoning).
For DeepSeek-R1, they employed a multi-stage pipeline. They started with a “cold start” SFT on thousands of reasoning examples. Then they carried out RL as with DeepSeek-R1-Zero, though they added a consistency reward that forces the model to generate more readable chain-of-thought (CoT) sequences.
Next, they carried out another round of fine-tuning to improve the model’s ability in writing, role-playing, and general tasks. The data for this task were taken from the SFT dataset and generated by the model itself and filtered through rejection sampling. Finally, they ran a final round of RL to align the model with user preferences.
Setting a new open standard
The DeepSeek models demonstrated that remarkable innovation and efficiency could thrive without hiding your model weights, architecture, and training recipes. DeepSeek provided both powerful models and a valuable blueprint for the community. Their success encourages more transparency and reproducibility, accelerating the pace of discovery for everyone.
To learn more about the innovations behind the DeepSeek models, read the full paper, titled “A Review of DeepSeek Models’ Key Innovative Techniques,” as well as the following:
– The DeepSeek-V3 Technical Report
– The DeepSeek-R1 paper
– The DeepSeek-Math paper (for more information on GRPO)