


This article is part of Demystifying AI, a series of posts that (try to) disambiguate the jargon and myths surrounding AI.
Since its release, DeepSeek-R1 has sent shockwaves across the AI industry, creating excitement in the open source community and panic among leading AI labs. However, there is also a lot of confusion around the model, what it does, and how it was trained. Here’s a brief rundown on what you need to know about this milestone release.
What is DeepSeek-R1 and what makes it special?
R1 is a large reasoning model (LRM) developed by DeepSeek, an AI lab owned by the Chinese hedge fund High-Flyer. R1 was built on top of DeepSeek-V3, a general-purpose large language model (LLM) that rivals state-of-the-art models such as OpenAI’s GPT-4o and Anthropic’s Claude 3.5 Sonnet.
The main R1 model is a 671-billion-parameter mixture of experts (MoE) model, which means that for any given task, it only uses a subset of its parameters that are relevant to that task. Opposite to MoE are “dense models,” which use all their parameters for each generation. MoE makes LLMs more resource-efficient.
One thing that sets R1 apart from other models is the way it was trained. The gold standard for fine-tuning LLMs for reasoning tasks is to train them on a large set of chain-of-thought (CoT) traces. CoT traces are the written process that the model goes through when it solves the problem. In most cases, the engineers rely on a large number of human-generated CoT traces to bootstrap the training. This is often referred to as supervised fine-tuning (SFT). They then use reinforcement learning (RL), where the model generates its own CoT and evaluates their quality.
The DeepSeek team figured out that they could skip the SFT step and directly jumped to RL. It turned out that the model could become just as good at learning CoT reasoning without human guidance. This was the method used or DeepSeek-R1-Zero, a variant of the model that was released at the same time as R1. R1 builds on top of R1-Zero, but uses SFT on a small set of high-quality CoT examples to make the reasoning process more understandable. It turns out that R1-Zero performs better than R1 on reasoning tasks, albeit its CoT trace is a bit less interpretable and often jumps between languages as it reasons over a problem.
As of today, both R1 and R1-Zero compete with the best reasoning models, including o1 and o3-mini. According to DeepSeek’s report, R1 is close behind o1 on key reasoning benchmarks.
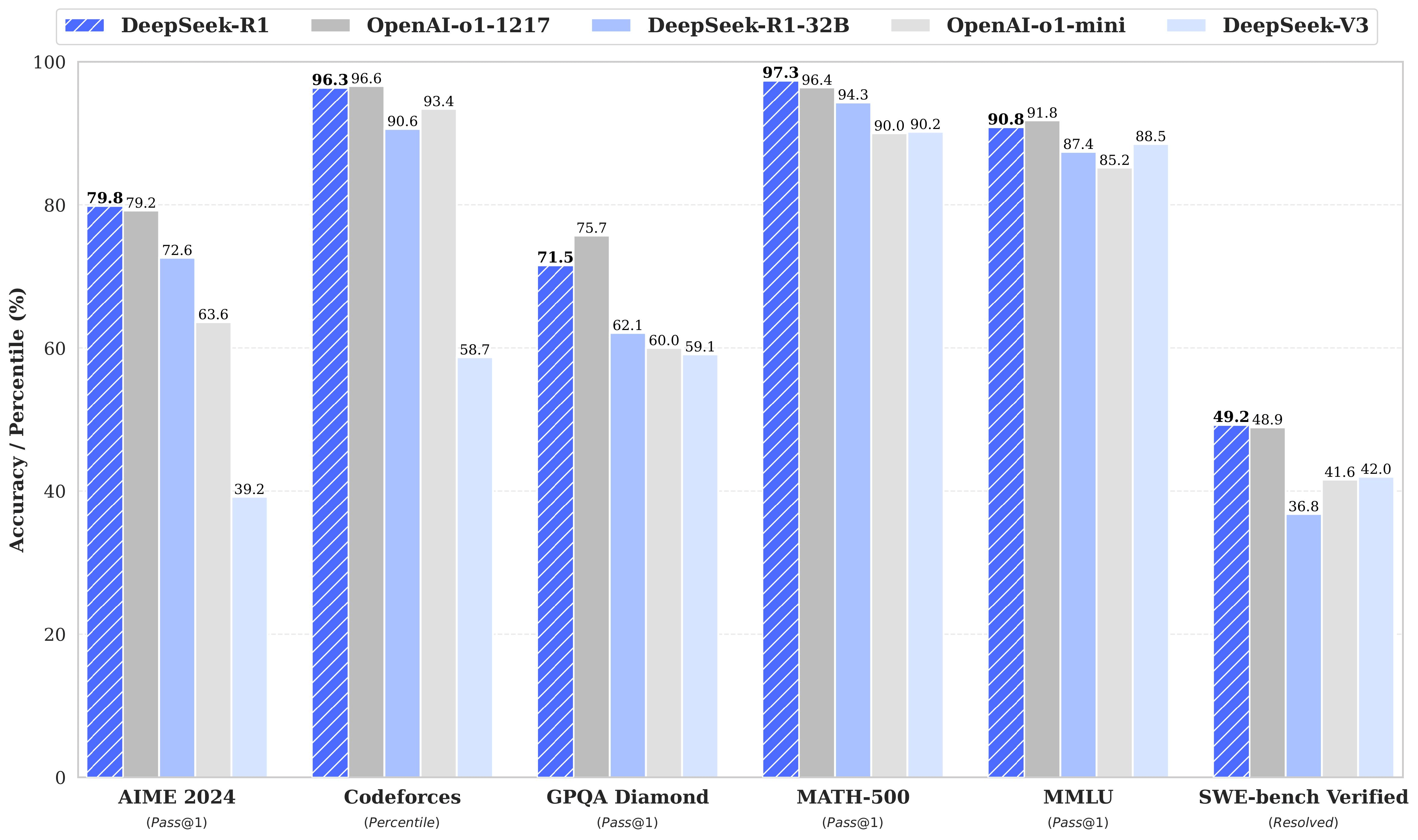
But more importantly, R1 reveals its full reasoning chain while o1 only shows a high-level overview of the reasoning process. In my experiments, I found this to be a key differentiator. When the model makes mistakes—and it happens quite a lot in real-world applications—being able to review the CoT is crucial for troubleshooting and correcting the prompt and data. (o3-mini recently started showing a more detailed version of the reasoning chain, but it is still not the raw tokens.)
How much did it cost to train DeepSeek-R1?
One of the biggest controversies around DeepSeek-R1 is the cost of training. It was initially reported by the media that the model was trained for less than $6 million as opposed to the billions of dollars it reportedly takes to train state-of-the-art models.
But this figure only accounts for the cost of the final training run. Training models requires a lot of experimentation at different scales, which is several times more expensive than the final training run. Moreover, the figure does not include other costs such as research and development and data acquisition.
There also isn’t much clarity on the compute cluster used to train the model. According to DeepSeek, the model was trained on a cluster of 2,048 Nvidia H800 GPUs. But other reports hint that DeepSeek might have acquired up to 50,000 H100 GPUs despite U.S. export restrictions.
Nonetheless, it is clear that DeepSeek trained its model at a much lower cost than other state-of-the-art models. Due to restrictions and limited access to high-bandwidth accelerators, the researchers and engineers made a lot of innovations to use their existing hardware more efficiently. Some of these include low-level code that makes better use of hardware, and a more efficient MoE architecture and attention mechanism.
Did DeepSeek-R1 steal data from OpenAI?
There are several claims made by different users on social media that DeepSeek-R1 was trained on data stolen from OpenAI through its API service. Some of these claims are made based on screenshots that show R1 responding to users that it is GPT-4o or another OpenAI model.
It is worth noting that R1 (and many other models) are trained on Common Crawl, a very large repository of text gathered from different sources across the web. This repository is regularly updated, and some of the text it contains is now generated by LLMs such as GPT-4o and includes excerpts such as “I am GPT-4o” or “I was trained by OpenAI.” So it is natural that a model trained on Common Crawl would manifest such behavior unless it has undergone some special post-training process.
Another point worth mentioning is that since OpenAI does not reveal the CoT trace of its reasoning models, it would not be possible for DeepSeek to create a training dataset through raw access to the API.
Nonetheless, OpenAI and Microsoft have made claims that there is evidence that DeepSeek has been gathering data en masse from the API endpoints. So the jury is still out on what really happened behind the scenes.
Is DeepSeek-R1 open source?
DeepSeek has released the weights for R1 and R1-Zero, including the full 671B model, as well as smaller distilled versions. Anyone can download and run the models on their servers. The release also includes 1.5-8B models that can run on edge devices, giving you reasoning models on your phone or laptop.
R1 also comes with a permissive MIT license, which allows you to use it for commercial purposes. Perplexity has already integrated it into its AI search product, and cloud providers such as Fireworks, Together AI, and Microsoft Azure have added it to their hosted model offerings. And already, hundreds of derivatives of R1 have been released on Hugging Face.
However, open weights does not mean “open source.” DeepSeek has not released the training data and code for R1. However, given the details they have included in their paper, other researchers are trying to reproduce the results. One notable example is Open R1 by the Hugging Face team, which plans to develop a fully open source version of R1 based on their paper.
Does DeepSeek-R1 steal your information?
If you’re using the DeepSeek app, website, or the R1 model hosted on Chinese servers, you can expect your data to be mined by the company and possibly handed over to the Chinese government. (On a side note, when you’re using OpenAI, Perplexity, or any other app, you should also be careful about the data you share with the provider.)
But when you download the model and run it on your server or device, you control the data. However, you should still be careful about the model’s behavior even if you’re hosting the model. For example, a model can be poisoned during training to generate malicious code that siphons your data in response to specific prompts. You should be careful and review the output of the model before taking any action on it, especially if it’s code (and this is not just limited to R1).