











?")








This article is part of our coverage of the latest in AI research.
A new technique proposed by researchers at MIT, Harvard, Stanford, and DeepMind uses multiple agents to solve one of the most pressing problems of large language models (LLMs): shortage of quality training data. AI labs have run out of data to train LLMs as frontier models have already consumed most of what’s useful on the web.
Among the different solutions to unlocking this bottleneck is creating synthetic data. One of the approaches is self-improvment, where LLMs generate quality examples to train themselves. For example, the LLM is prompted to solve a math, reasoning, or coding problem. The model generates reasoning chains and responses, evaluates the results, and adds valid examples to a training dataset that is used to fine-tune the model in the next training cycle.
This is an effective but limited approach. Different studies show that such methods plateau after a few training iterations, limiting the applicability of self-improvement methods.
Multiagent debate and fine-tuning
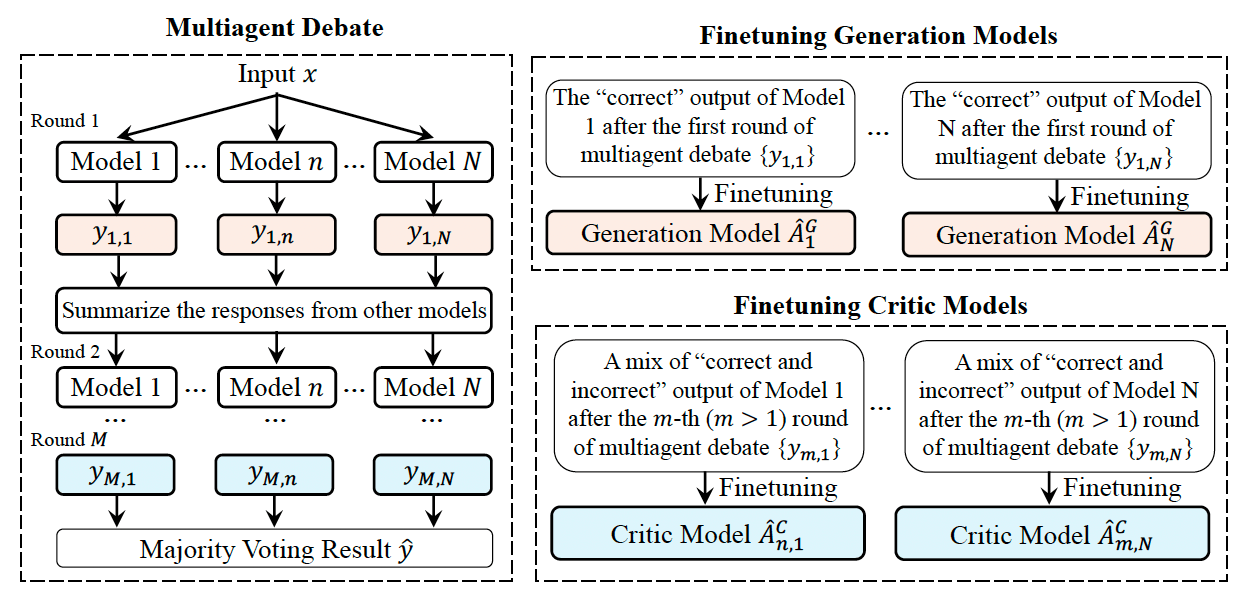
To improve performance, the new technique uses the concept of multiagent debate, where several LLM agents draft and refine responses together. Instead of fine-tuning a single model, the framework uses the same debate and refinement framework to generate diverse datasets and fine-tune multiple models. The models are derived from the same base model and each is trained to specialize in certain parts of the target task.
The framework is composed of generation and critic agents. For each problem, the first group of LLMs—the generation agents—create initial responses. The role of the generation models is to accurately respond to input questions. Each model is prompted in a different way to create a diverse set of reasoning chains and responses.
Then the critic agents assess the outputs from all generation agents and select the most effective response or generate feedback for improvement. The role of the critic agents is to provide accurate critiques of LLM-generated responses and use these responses to provide an updated answer. The agents can engage in multiple rounds of debate and feedback to further refine the answer.
The updated responses and critiques are then used to create a dataset to fine-tune both the generation and the critic agents. Once both sets of agents are trained, they repeat the cycle to create better responses. To ensure diversity, each of the generation and critic agents is fine-tuned on a different set of examples that have been produced based on its interactions. As they repeat the cycle, they create better and better datasets and each agent becomes better at specific parts of the task.
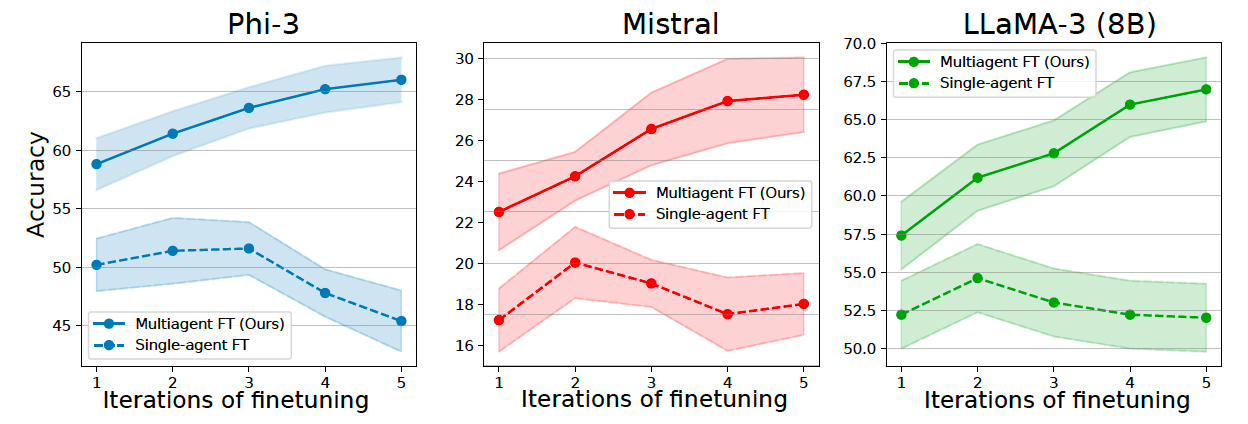
Unlike the classic self-improvement framework, the quality of the training data continues to improve across many iterations given the diversity of the behavior it creates.
“We found that iterative application of the multiagent finetuning allows for continuous learning and adaptation, leading to progressively refined and more accurate responses over time,” the researchers write.
The researchers further note that by “training each model on distinct sets of data and roles, our approach fosters specialization across models and promotes diversification within the society of models. Consequently, our system can autonomously improve over many more rounds of finetuning compared to single-agent self-improvement methods.”
During inference, the framework uses the ecosystem of generation and critic agents to draft multiple responses and refine them through multiagent debate. Each agent takes the responses from all other agents and generates a new response in each round of the debate.
“We found that summarizing the responses from the other agents helps eliminate redundant information while retaining the most important details, thereby further improving performance,” the researchers write.
Multiagent fine-tuning in action
The researchers tested the approach on several reasoning benchmarks for arithmetic, grade-school math, and competition-level math problems. They used it with open source models (Mistral 7B, Llama 3-8B, and Phi 3-4B) as well as GPT-3.5. Since multiagent debate and fine-tuning does not require access to the internal weights of the models, it was applicable both to open and closed models.
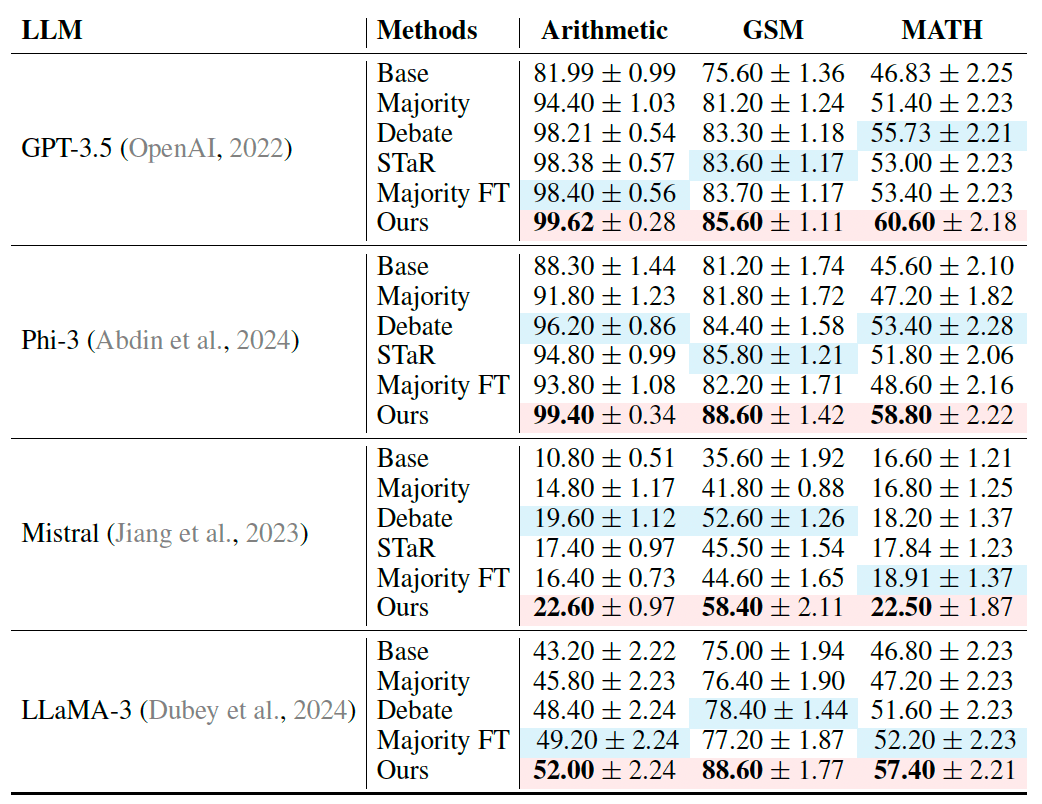
The results showed that the multiagent approach outperformed other techniques, including majority voting (where the model produces several independent answers and chooses the best one) and approaches where agents refine their answers but do not go through the fine-tuning process. Moreover, the fine-tuned models could generalize to unseen tasks and outperform baseline methods that directly train the models on the target task. For example, an agent ecosystem fine-tuned on the MATH dataset performed very well on the GSM benchmark.
Importantly, multiagent continued to show improved performance throughout multiple iterations, while other self-improvement methods started regressing after a few cycles.
One tradeoff of the multiagent approach is the cost since it requires multiple copies of models to train and run at the same time. It will be interesting to see if optimization techniques such as LoRA and quantization can help overcome this challenge. However, what’s important is that for the moment, multiagent fine-tuning seems to address one of the important problems that the AI community faces.