











?")








This article is part of our coverage of the latest in AI research.
One of the key reasons for the success of the Transformer architecture, the backbone of today’s large language models (LLMs), is its “attention mechanism,” which has made it possible to scale the models to many layers and parameters (and got the original Transformer paper the title “Attention Is All You Need”). However, a new study by researchers at the University of Maryland shows that Transformer models can shed a substantial portion of their attention layers without degrading their performance. This results in smaller, faster, and more memory-efficient models.
Redundancy in Transformers
Transformer models are composed of uniform blocks stacked on top of each other. Each block contains attention layers and dense (MLP) layers.
In their study, the researchers explored redundancy in transformers at three levels: Transformer blocks, MLP layers, and attention layers. To measure redundancy, they used a similarity metric that compares the input and output of a module.
“The underlying hypothesis is that redundant modules produce outputs that are similar to their inputs, implying minimal transformation,” the researchers write. “In contrast, important modules are expected to significantly alter their inputs and thus should be preserved.”
Based on this metric, they pruned trained Transformer-based language models at each of the three levels.
They first considered dropping entire blocks deemed redundant (Block Drop). However, their experiments showed that Block Drop degrades performance significantly as it overlooks the internal fine-grained architectures within each block.
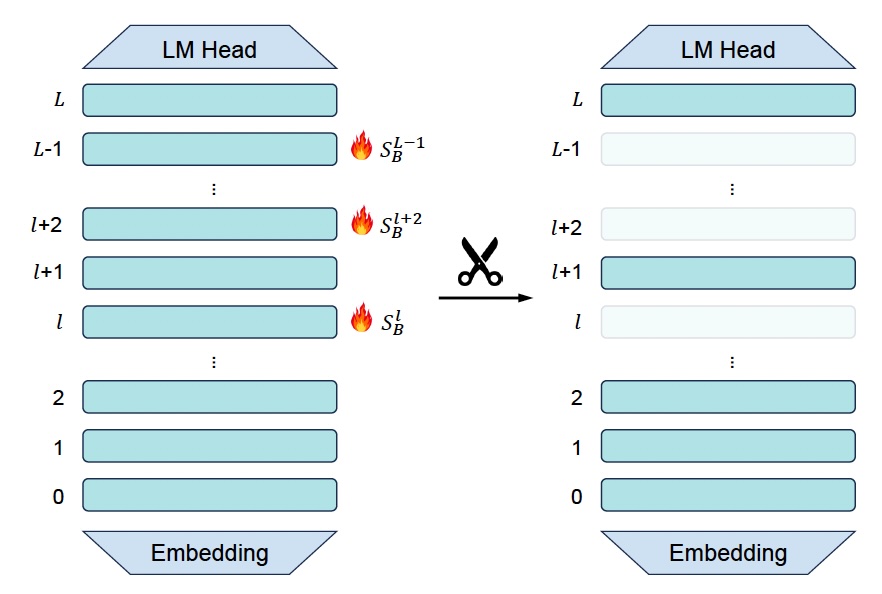
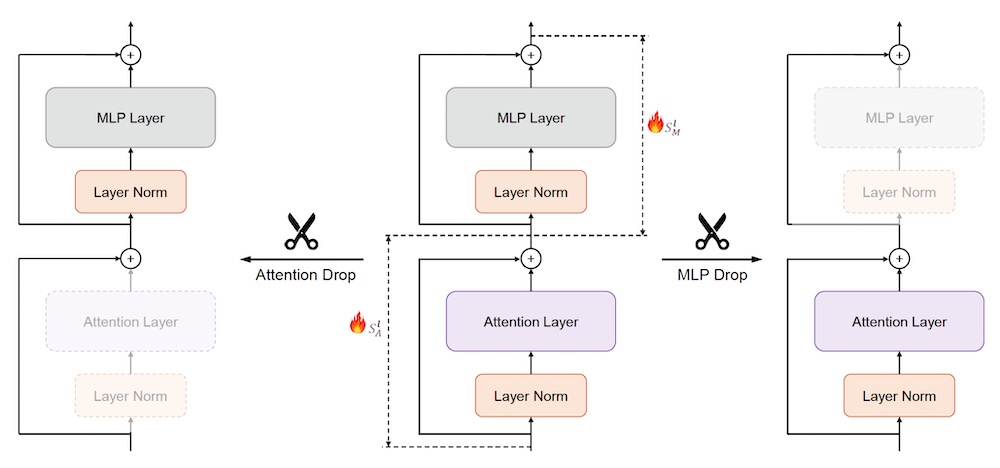
They developed two targeted techniques, MLP Drop and Attention Drop, that remove specific MLP or attention layers within blocks based on their redundancy score. Their findings show that dropping MLP layers hurts performance. But surprisingly, they were able to prune a substantial portion of attention layers without degrading the model’s performance.
For instance, on the Llama-2-70B model, they were able to remove 50% of the attention layers while preserving performance at a level comparable to the full model. The Llama-2-13B and Mistral-7B models maintained over 99% of their original performance even after dropping eight attention layers.
“These results demonstrate that attention layers are highly redundant, and their removal has minimal impact on model accuracy, making Attention Drop a highly efficient pruning strategy,” the researchers write.
Another benefit of the Attention Drop pruning method is that it reduces the size of the KV cache, the memory used to preserve attention computations to speed up inference. For instance, in Llama-2-13B, the KV cache is reduced from 52GB to 26GB, a 50% reduction.
The researchers also propose “Joint Layer Drop,” a flexible approach that removes both MLP and attention layers.
“By combining the importance scores of these layers, we find that jointly dropping low-importance Attention and MLP layers yields better performance under high sparsity conditions compared to pruning only one type of layer,” the researchers write.
For example, they found that Llama-2-13B still retains 90% of the performance on the MMLU benchmark even after dropping 31 attention and MLP layers.
One key insight from the paper is that the high redundancy in attention layers, particularly in deeper layers, can help guide future research on creating more compact models that have fewer layers while preserving their performance.
Model compression
This work is part of the broader efforts to compress large language models. The most widely used techniques are quantization and pruning. Pruning focuses on removing non-essential components of the model while quantization converts the model’s parameters into lower-precision data types.
One of the challenges of pruning is that it can disrupt the model’s structure and make it difficult to use accelerator hardware efficiently. Block Drop and Layer Drop, two of the methods proposed in the paper, remove structured modules rather than fine-grained parameters, making them hardware-friendly. The technique can also be combined with quantization methods to further improve the model’s efficiency.