









?")


")







This article is part of our coverage of the latest in AI research.
A new study by OpenAI researchers takes a deep dive into the software engineering capabilities of frontier AI models. And interestingly, Claude 3.5 Sonnet beats OpenAI’s GPT-4o and even its reasoning model o1 on SWE-Lancer, the new benchmark the researchers have released.
There are already several benchmarks for evaluating the coding abilities of large language models (LLMs). For example, MBPP and HumanEval are composed of tasks that require writing single functions. These benchmarks have mostly been saturated by advanced models and don’t reflect the complicated nature of creating and modifying software.
Currently, the most realistic software engineering benchmarks are SWE-Bench and SWE-Bench Verified. OpenAI’s o3 model achieves 72% on SWE-Bench Verified. However, SWE-Bench and SWE-Bench Verified still don’t reflect the full reality of software engineering projects. They mostly focus on pull requests from open-source repositories and are composed of isolated, self-contained tasks.
SWE-Lancer is designed to better measure the real-world software engineering capabilities and impact of AI models. It includes 1,488 freelance software engineering jobs from Upwork, collectively worth $1 million in payouts.
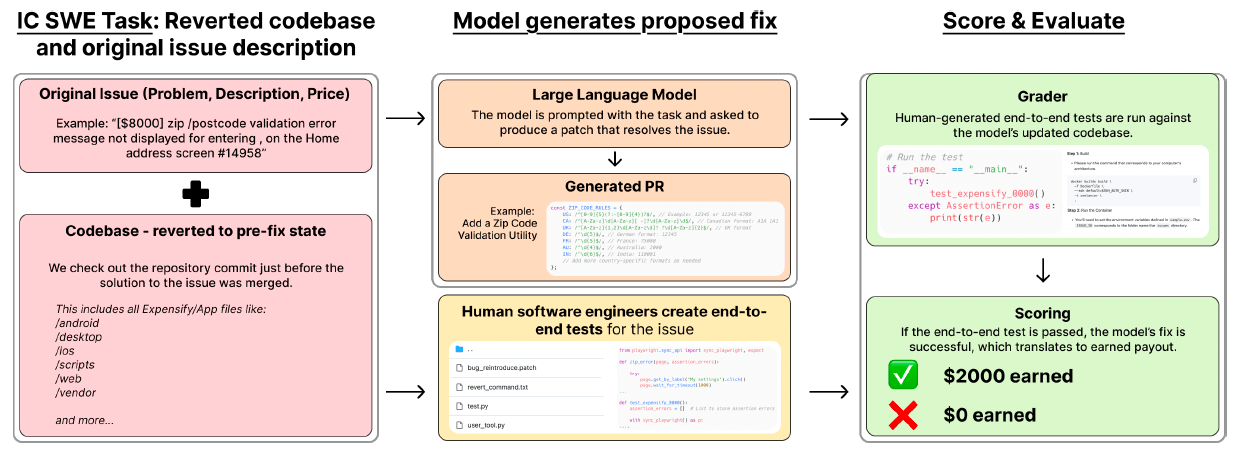
The tasks are broken down into two categories: individual contributor software engineering (IC SWE) tasks and software engineering management tasks (SWE Manager). IC SWE includes tasks such as implementing features or resolving bugs. The model’s responses are evaluated through end-to-end tests created by a team of professional software engineers.
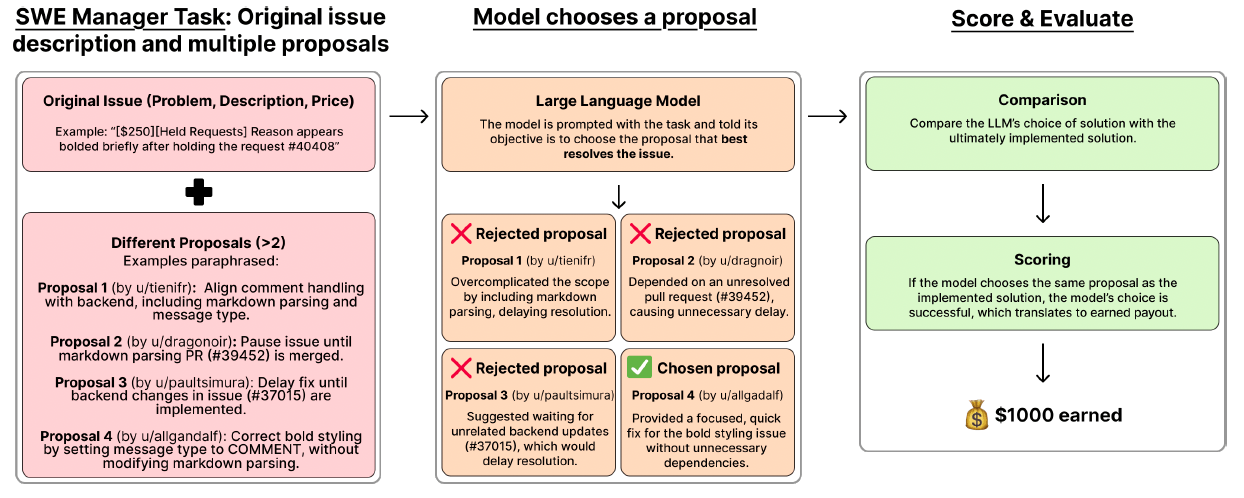
In SWE Manager, the model must review competing proposals submitted for job postings and select the best one. Its response is compared to the choices of the original engineering managers. SWE Manager tasks require a deep technical understanding of both the issue and the proposals. In some cases, multiple proposals are technically correct, and the model must consider the context of the entire repository when choosing the best proposal.
The OpenAI researchers designed SWE-Lancer to make it more representative of real-world software engineering. It contains a wide range of tasks (UI/UX, application logic, server logic, bug fixes, etc.). It also uses end-to-end testing instead of unit tests to prevent shortcuts that would allow the models to produce the correct response without solving the intermediate steps.
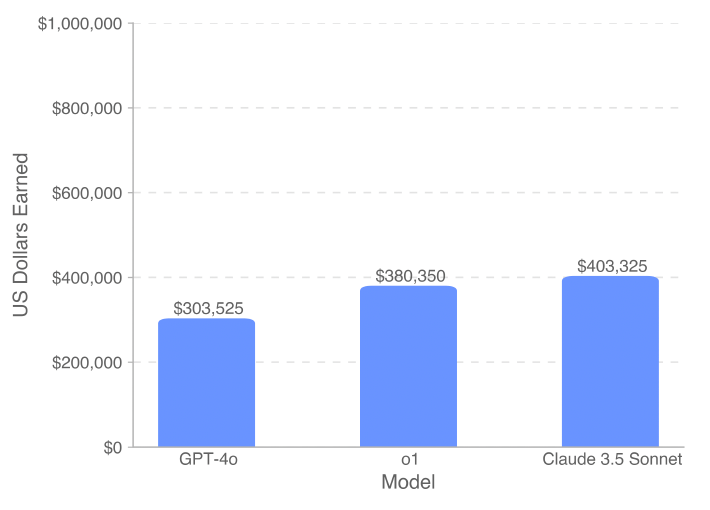
The researchers tested GPT-4o, o1 (with “high” reasoning), and Claude 3.5 Sonnet. In both task categories, Claude performed better than the other two models, scoring 26.2% on IC SWE and 44.9% on SWE Manager (which is still relatively low in comparison to performance on other benchmarks). Claude 3.5 Sonnet was able to generate over $400,000 out of the possible $1,000,000 on the full SWE-Lancer dataset, compared to $304,000 for GPT-4o and $380,000 for o1.
Interestingly, the findings show that LLMs are better at performing senior management jobs instead of solving the tasks themselves (this is partly due to the fact that in coding tasks, it is much easier to verify the correctness of a solution than solving the problem).
According to the researchers, LLMs can localize the problem but can’t find the root cause, which results in partial or flawed solutions.
“Agents pinpoint the source of an issue remarkably quickly, using keyword searches across the whole repository to quickly locate the relevant file and functions – often far faster than a human would,” they write. “However, they often exhibit a limited understanding of how the issue spans multiple components or files, and fail to address the root cause, leading to solutions that are incorrect or insufficiently comprehensive.”
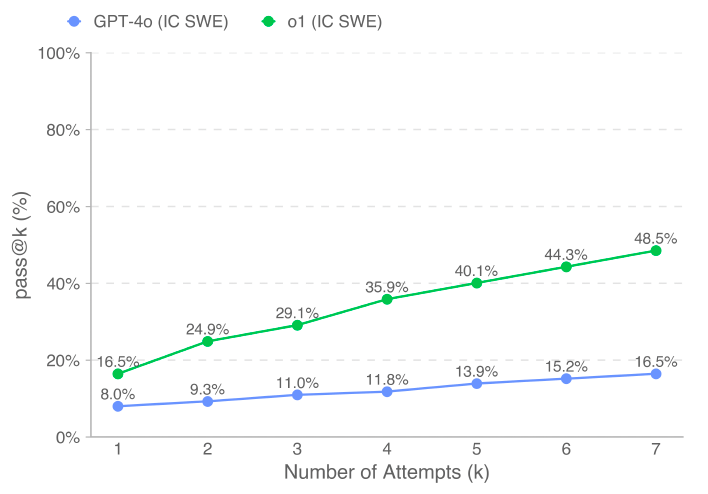
Another important finding is that the performance of all models increases if they are allowed to generate more answers and choose the best one. This improvement is especially visible for o1, where allowing for six more attempts nearly triples the percentage of solved tasks. (This is a reminder of one of the benefits of LLMs: They can sometimes make up for their weaknesses by repeating the process multiple times until they get the right answer.)
o1 also shows improved performance when given the option to use a user tool to check the result of its fixes.
The researchers have released SWE-Lancer Diamond, a subset of the full dataset, which other researchers can use to develop and test models for advanced software engineering tasks. While experience has shown that all benchmarks will eventually get saturated, there is still a lot of room for improvement on SWE-Lancer, which will lead to better models.
“Results indicate that the real-world freelance work in our benchmark remains challenging for frontier language models,” the OpenAI researchers write. “The best performing model, Claude 3.5 Sonnet, earns $208,050 on the SWE-Lancer Diamond set and resolves 26.2% of IC SWE issues; however, the majority of its solutions are incorrect, and higher reliability is needed for trustworthy deployment.”