











?")








Retrieval augmented generation (RAG) is one of the important techniques for customizing large language models (LLMs) with external information. However, the performance of RAG depends on the quality of the retrieved documents. Beyond the standard retrieval method used in RAG pipelines, these four techniques will help improve the quality of the documents you retrieve.
Standard embedding-based retrieval
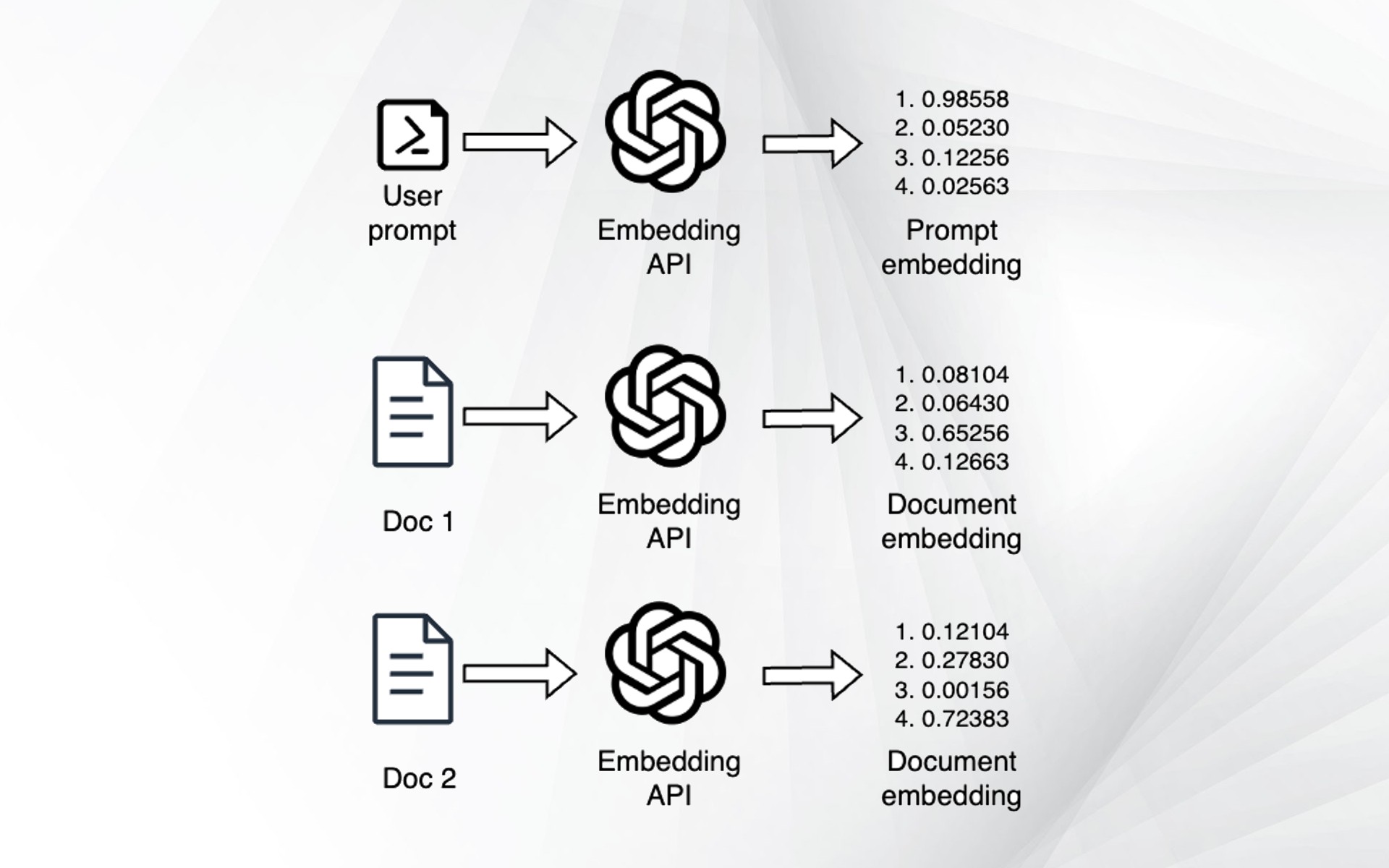
The standard retrieval method used in RAG pipelines is to do a similarity search between the user query and the embeddings of your knowledge corpus. In this method, you prepare your knowledge base through the following steps:
1- Your documents are first broken down into smaller chunks (e.g., 500-1,000 tokens)
2- An encoder model (e.g., SentenceTransformers or OpenAI embeddings) computes the embedding of each chunk
3- The embeddings are stored in a vector database (e.g., Pinecone or Qdrant)
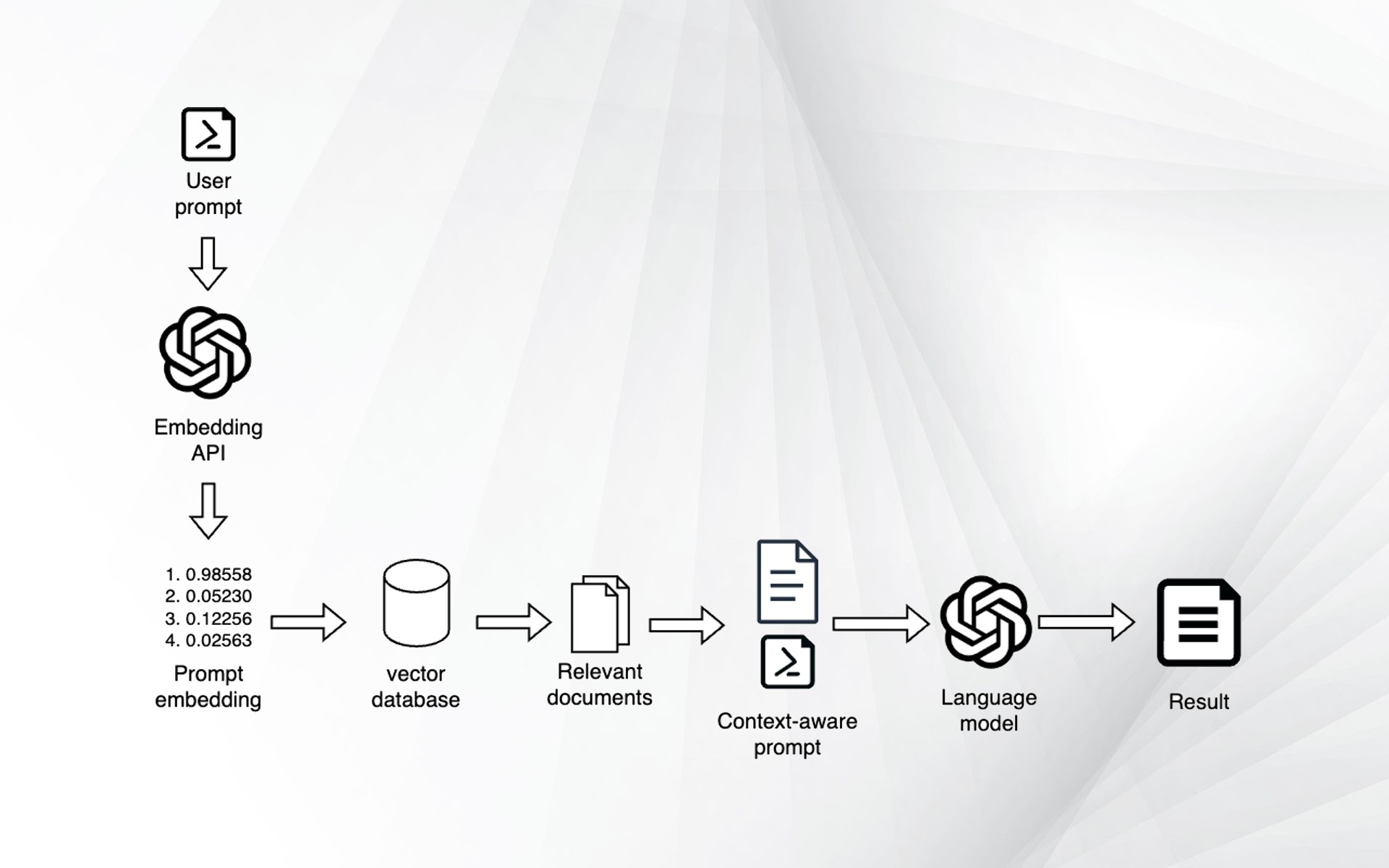
Once your vector database is ready, your RAG pipeline can start adding context to user queries:
1- The user sends a query to your application
2- The encoder model you used during the preparation phase computes the embedding of the query
3- The embedding is compared to the embeddings stored in the vector database to retrieve the most similar documents
4- The contents of the retrieved documents are added to the user prompt as context
5- The updated prompt is sent to the LLM
Document and query domain alignment
Sometimes, the documents that contain useful information are not semantically aligned with the user’s query. As a result, the similarity scores of their embeddings will be very low and the RAG pipeline will fail to retrieve them.
Document domain alignment solves this problem by modifying the prompt in a way that brings it closer to the relevant documents. One effective technique for document alignment is Hypothetical Document Embedding (HyDE).
Given a query, HyDE prompts a language model to generate a hypothetical document that contains the answer. This generated document may contain false details, but it will have the relevant patterns that fall within the neighborhood of the relevant documents in the knowledge corpus. In the retrieval stage, instead of the user query, the embedding of the hypothetical document is sent to the vector database to calculate similarity scores with the indexed documents.
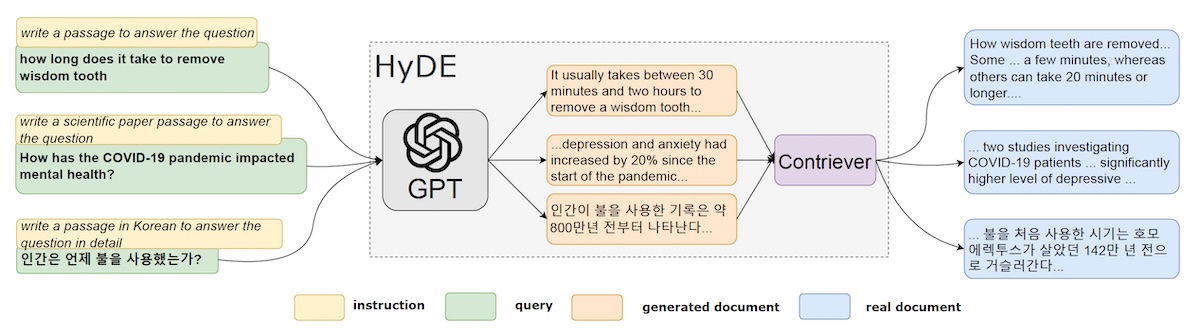
There is another way to improve the alignment between queries and documents. In “query domain alignment,” we use an LLM to generate a set of questions that each document can answer and store their embeddings in the vector store. During retrieval, the embedding of the query is compared to those of the questions, and the documents corresponding to the best matches are returned. Comparing questions to questions ensures better alignment between the query and the vector store.
Hybrid search
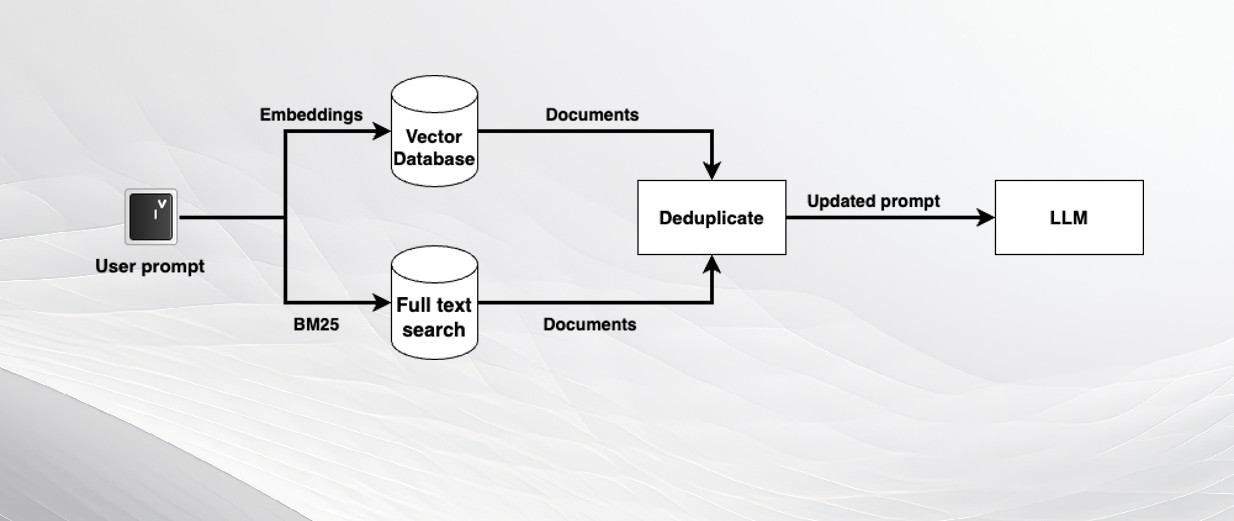
The classic RAG pipeline is very effective but has its limitations. Embedding models are very effective at capturing semantic information but can return imprecise results when looking for exact matches. For this, you can augment your RAG pipeline with classic search algorithms or SQL queries.
For example, you can use an algorithm like BM25, which can search through your documents based on the keywords of the user’s query. The benefit of BM25 is that it automatically downgrades common words that can appear in an LLM query and focuses on keywords that matter the most.
Alternatively, you can use text-to-SQL techniques, which use an LLM to create an SQL query from the user’s request. The query can then be sent to a relational database to retrieve matching records.
You can combine the documents retrieved by different retrieval methods, remove duplicates, and add them to the prompt as context. This ensures that you get the value of different retrieval methods.
Contextual retrieval
In many cases, the document chunks containing the answer to the query are missing important pieces of information. This is especially true if you’re dealing with large documents that are split into multiple chunks. In this case, the answer to the user’s query might need information from multiple chunks of the document.
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
For example, your knowledge corpus might include the quarterly earnings for Company X and you want to answer the question: “What was the revenue growth for Company X in Q1 2024?”
One of the chunks for the quarterly document might contain the correct answer: “The company’s revenue grew by 3% over the previous quarter.” But this chunk does not specify which company it was and what time period it was referring to.
In these cases, you can enhance retrieval by adding contextual information to each chunk before calculating the embeddings and indexing them. Contextual retrieval was recently introduced by Anthropic AI. In the above example, the document chunk that contains the answer would be prepended with information such as: “This chunk is from the quarterly earnings of Company X. It discusses the company’s earnings in Q1 2024.”
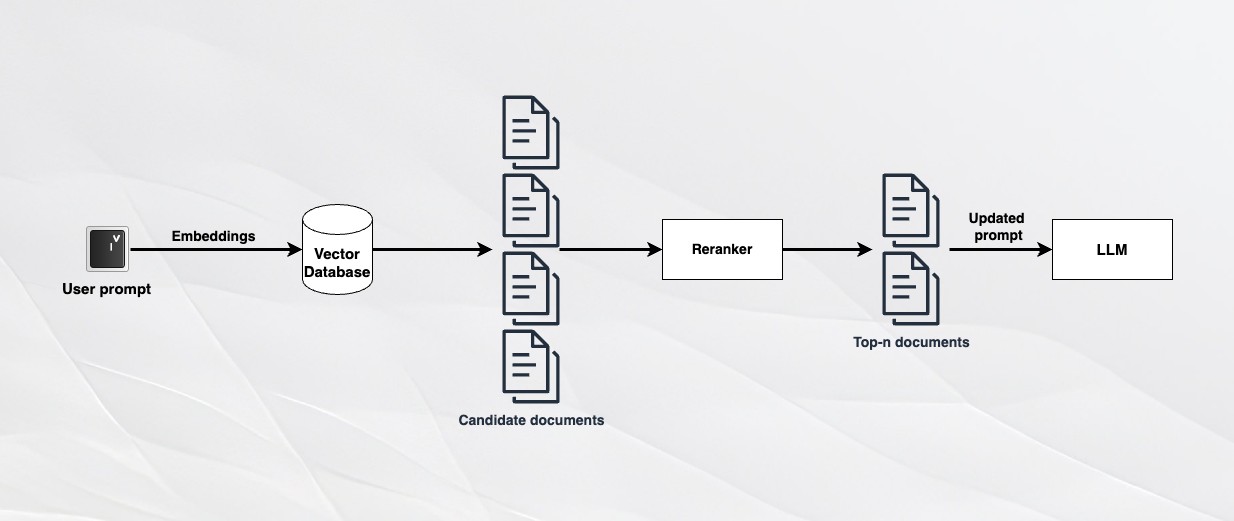
Reranking
No matter how much you improve your indexing and retrieval mechanisms, there is always a chance that you will miss important documents for some prompts. One workaround that is easy to implement and is widely popular is reranking.
Reranking algorithms compare the full text of documents against user queries. They are not efficient when run against a full corpus but can process a few dozen documents very quickly. Therefore, if you want to add n documents as context to your LLM, you can retrieve 2n or 3n documents and run them through a reranking algorithm to retrieve the top-n that are relevant to your query.
Cohere Rerank is a fast and easy-to-use API-based reranking tool. In case you want an open source reranking model, you can use bge-reranker.
Considerations
While using advanced retrieval techniques can improve the performance of your RAG pipeline, it is important to consider the tradeoffs. Adding layers of complexity can result in higher compute and storage costs or slow down your retrieval process. For example, document domain alignment adds an extra LLM call to your RAG pipeline, slowing down the process and adding considerable costs at scale. Classic search and reranking will add an extra processing step to the RAG. And contextual retrieval increases the costs of the preparation and indexing step by requiring many calls to your LLM to generate contextual information.
I usually start by setting an expected accuracy for my task and then determine whether the extra effort and costs are worth the payback. For example, in a writing assistance application where I expect an expert with full knowledge of the topic to review and correct the entire answer, I might not need the few percentage points of accuracy gained from adding extra processing layers to the RAG pipeline. On the other hand, if I’m developing an application where the accuracy of the retrieved documents is a big differentiator and the user won’t mind waiting a few extra seconds to get more accurate answers, it makes sense to add extra techniques.