










?")


")





This article is part of Demystifying AI, a series of posts that (try to) disambiguate the jargon and myths surrounding artificial intelligence.
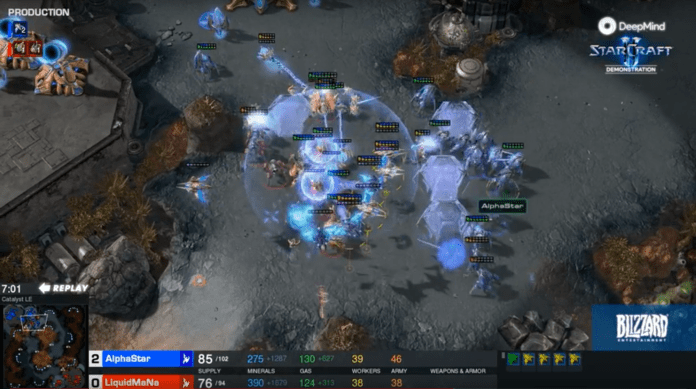
DeepMind, the artificial intelligence company best known for developing AlphaGo and AlphaZero, revealed on Thursday that it had created an AI that could play famous real-time strategy game StarCraft II well enough to beat some of the best human players in the world. Called AlphaStar, the AI clinched decisive victory against two grandmaster players in a series of matches played at DeepMind’s headquarters.
Games have historically been a testbed to evaluate the efficiency of AI algorithms. In the past years, AI researchers have managed to master board games such as checkers, chess and the ancient game of Go. More recently, video games have become an area of focus for AI researchers. There have already been progress in several single- and multi-player games such as Mario, Quake, Dota 2 and several Atari games. In this regard the mastering of StarCraft II is a milestone for several reasons.
Here’s what we know about AlphaStar and why its achievement is important.
The challenges of teaching AI to play StarCraft II
In 2016, DeepMind’s AlphaGo AI beat the world champion in Go, a Chinese board game that scientists thought would be beyond the capacity of artificial intelligence for decades to come. In the following year, the company repurposed the same AI to learn chess and shogi (Japanese chess) with very little input from humans.
But all of those games have two common traits that limited their complexity: They are turn-based and give players perfect information. In chess and Go, each player waits for the other to finish before making their move. Also, every player can always see the entire board and every piece at all times.
In contrast, StarCraft II is a real-time strategy game, which means players must make decisions simultaneously. They also have imperfect information. Their view on the game map is limited to the areas their units have previously discovered. Even after revealing unknown parts of the map, they will only be able to see as much activities in areas where their units are present. For instance, a player won’t be able to see what’s going on in their opponents’ base unless their units are actively attacking it. It also means an enemy can sneak up on you through areas where you don’t have visibility.
StarCraft also provides a richer and more complex environment. Contrary to board games, where every square is treated equally, in games like StarCraft, movement and performance of units changes based on factors such as the type of ground and elevation. The map is also much larger than an 8×8 or 19×19 grid, which means brute force methods of trying to predict every single move and making the best choice are simply inefficient.
All these and other subtle elements have made StarCraft a huge challenge for AI algorithms. As opposed to other video games such as Quake and Mario, where quick reflexes and precision play a key role in winning a game, StarCraft requires both short- and long-term planning and well-timed clicks.
How did DeepMind’s AI “learn” to play StarCraft II?

Older game-playing AIs use classical rule-based approaches, which means human engineers must manually code the rules of the game into the software. An example is Stockfish, an open-source chess-playing bot developed and enhanced by hundreds of developers over several years.
While manually embedding gameplay and tactical rules into AI might work for simpler games, it simply won’t work for a game that is as complex as StarCraft. Like many other contemporary AI applications, AlphaStar uses deep learning to learn to play StarCraft II. In deep learning, an AI develops its behavior by analyzing and comparing a large number of examples. In the case of AlphStar, the AI was “trained” by providing it with data from numerous games.
According to DeepMind, AlphaStar uses a combination of “supervised learning” and “reinforcement learning.” Supervised learning is the type of of deep learning where models train on samples prepared by human users. The DeepMind team initially provided AlphaStar with anonymized human game data released by Blizzard. By processing the data, the AI was able to imitate the basic micro and macro-strategies StarCraft uses employ. According to DeepMind, this initial training placed AlphaStar on par with StarCraft’s most difficult built-in AI.
With the basics learned, AlphaStar engaged in reinforcement learning to hone its skills. In reinforcement learning, AI models develop their behavior without getting help from human data. Many consider reinforcement learning the holy grail of contemporary artificial intelligence, because quality human input and labor is scarce, expensive and slow, and it entails ethical and privacy concerns (that’s why DeepMind explicitly states that the game data used for supervised learning was “anonymized,” which means information that would reveal users’ identities were removed).
Reinforcement learning overcomes the shortcomings of supervised learning by creating its own training data. DeepMind created an AI league where several instances of AlphaStar tirelessly played against each other in rapid succession to develop their skills. This is the equivalent of several professional StarCraft players playing in super fast forward.
The final AlphaStar consolidated the most successful strategies from all the AI agents in the league into a final model.
The difference between AI and humans playing StarCraft

“I was impressed to see AlphaStar pull off advanced moves and different strategies across almost every game, using a very human style of gameplay I wouldn’t have expected,” said professional StarCraft II player Grzegorz Komincz (MaNa), who lost 5-0 to AlphaStar.
Professional StarCraft commentators were also astounded by AlphaStar’s play and described it as “phenomenal” and “superhuman.”
But while AlphaStar is a very remarkable piece of technology and a milestone achievement for the artificial intelligence industry, it’s important not to confuse it with human intelligence and how human players learn and play StarCraft.
To reach the level of proficiency it displayed on Thursday, AlphaStar went through more matches than any human can play in an entire lifetime . Having been acquired by Google in 2014, DeepMind had access to its parent company’s vast compute resources for training their AI models. Each of the AI agents in the AlphaStar league was trained with 16 of Google’s powerful TPUs, processors specialized for AI tasks. During a 14-day process, each agent experience 200 years’ worth of games. According to a AMA Reddit thread with DeepMind researchers, each agent played the equivalent of 10 million games.
When considering the sheer number of games AlphaStar had to play to achieve the edge it gained over human players, the limitations of deep learning become accentuated. Humans are able to understand abstract concepts and make decisions based on commonsense and incomplete knowledge, on gut feelings and personal experiences. That’s why they can get the general sense of StarCraft and quickly develop a mental model for successful tactics by playing a few matches and watching a few hours’ worth of professional gameplay.
Deep learning, on the other hand, makes decisions based on statistics and probabilities. The more StarCraft games an AI plays, the more examples it has to compare its decisions against. That’s why it needs to play so many games to achieve proficiency.
“The limitations of ML is still going to be the data you feed to it. It has no understanding of the objects and what they mean to humans. We humans, even while playing a game, identify objects with a meaning behind them or we relate each object to a real-world activity it’s used for to perform specific actions. To AI, they’re just shapes and pixels, and if new objects are introduced to the game, it has no idea on how to adopt this change in future moves without going through millions of iterations of training and test phase,” says Jai Rangwani, CTO, AI Trader.
Deep learning is also only good at performing limited tasks, widely known as narrow AI. Unlike humans, current blends of artificial intelligence are very bad at transferring knowledge from one domain to another. A professional StarCraft II player will be able to quickly adapt to the rules of StarCraft, Warcraft III and most other RTS games in very limited time. But while AlphaStar has been able to defeat the best StarCraft II players, it will have to learn other strategy games, even StarCraft I, from scratch.
AlphaStar has only been trained to play Protoss, one of the three races available in the game. While pro players also excel at one of three races, they can quickly adapt their skills to the other races. For AlphaStar, playing Zerg or Terran, the other two races, means it has to go through the entire extensive training all over.
Even small changes to the rules and environment can have a huge impact on the performance of the AI. For instance, human players only see a limited part of the map, enough to fit in their screen. By default, AlphaStar could see the entire zoomed-out game map simultaneously (excluding the areas it hasn’t discovered yet). After MaNa’s 5-0 loss to AlphaStar, the AI was changed to have the same limited view window as the human user. The change resulted in a definitive loss for AlphaStar.
“The bigger issue that we have seen… is that the policy learned [by the AI] is brittle, and when a human can push the AI out of its comfort zone, the AI falls apart,” associate AI professor at Georgia Tech Mark Riedl told The Verge.
Why AI’s mastering of StarCraft II and other games is important

The team at DeepMind has done a tremendous job. However, it’s important to understand and recognize the differences between AI and human intelligence. AlphaStar can’t develop the human mental model of StarCraft II, but it can certainly make up for its shortcomings through sheer speed and parallel processing. That’s why it was able to play hundreds of years’ worth of games in a matter of two weeks and also merge the knowledge of several AI agents into a final model.
AI like AlphaStar is also very good at micromanagement, which means it can control very granular details simultaneously. For instance, the AI can give hundreds of individual commands to different units in a fraction of the time it would take for a human to do so. According to DeepMind’s blog, the AI was handicapped to prevent it from giving too many commands, but should it be permitted to unleash its full power, it would be able to outmatch its human opponents much easier.
But what’s the real use of teaching AI to play real-time video games such as StarCraft II?” AlphaStar displays AI’s proficiency at predicting and performing very long sequences of action. “The fundamental problem of making complex predictions over very long sequences of data appears in many real-world challenges, such as weather prediction, climate modeling, language understanding and more,” say the DeepMind researchers in their blog post.
Other game-playing AIs have already show real-life uses. DeepMind previously used the innovation behind AlphaGo to help optimize power grids and reduce electricity consumption.
In 2018, a deep learning system developed by non-profit research organization OpenAI developed competed with professional players at Dota 2, a real-time multiplayer online battle arena. While the AI, codenamed OpenAI Five, lost against human champions, but its underlying technology helped spur other advances in AI, including the development of a robotic hand that could teach itself to handle objects without help from humans.
As the artificial intelligence continues to advance, it will be bound to solve bigger problems. The first step to figuring out how to solve those problems might start with learning to play a game.