









?")


")







This article is part of our coverage of the latest in AI research.
Reducing the length of prompts you send to large language models (LLM) can result in faster inference times and lower costs. This is why prompt compression has become a popular area of LLM research.
In a new paper, researchers at Tsinghua University and Microsoft introduce LLMLingua-2, a new task-agnostic prompt compression technique. LLMLingua-2 is faster and more efficient than other prompt compression methods and requires less computational resources. It can be a good tool for LLM applications that involve lengthy prompts and compression can result in major cost savings and better user experience.
Task-aware and task-agnostic prompt compression
Techniques like chain-of-thought (CoT) reasoning, in-context learning, and retrieval-augmented generation (RAG) enable LLMs to handle complex tasks and knowledge that was not included in their training data.
However, the benefits of lengthy prompts come at the cost of increased computational and financial requirements. And in some LLMs, longer prompts can reduce the accuracy of the model’s ability to handle contextual information.
Prompt compression addresses these issues by shortening the original text while keeping essential information. The underlying assumption of prompt compression is that natural language contains redundancy that may be useful for human understanding but not necessary for LLMs.
Prompt compression can be categorized into “task-aware” and “task-agnostic” methods. Task-aware compression removes tokens from the prompt based on the downstream task or the current query. A popular method is LongLLMLingua, which applies a question-aware multi-step approach to estimate the information entropy of the tokens and remove redundant pieces. Other methods use reinforcement learning to train a model to compress the prompt based on reward signals from downstream tasks. The tradeoff of task-aware compression is their limited generalizability to other tasks.
On the other hand, task-agnostic methods compress the prompt without considering the specific task, making it more adaptable to a wider range of applications and black-box LLMs. Some task-agnostic include LLMLingua and Selective-Context. These methods use a causal small language model (SLM) such as Llama-7B to evaluate the entropy of tokens or lexical units and remove those that don’t add meaningful information.
LLMLingua-2, which was developed by the authors of the original LLMLingua, is a task-agnostic prompt compression technique.
How LLMLingua-2 works
There are several limitations to current task-agnostic compression methods, which led the researchers to create the successor to LLMLingua.
“Information entropy may be a suboptimal compression metric because (i) it is not aligned with the prompt compression objective and (ii) it only leverages unidirectional context and may fail to capture all essential information needed for prompt compression,” Qianhui Wu, senior researcher at Microsoft and co-author of the paper, told TechTalks.
LLMLingua-2 reformulates prompt compression as a classification task that specifies whether each token should be preserved or discarded. It uses this task formulation to create a prompt compression training dataset. It then uses the dataset to train a lightweight bidirectional transformer encoder model for the compression task.
“In this way, it can capture all essential information needed for prompt compression from the full bidirectional context and guarantee the faithfulness of the compressed prompt to the original one,” Wu said.
LLMLingua-2 has several key benefits. First, using the bidirectional encoder ensures that it can capture all essential information needed for prompt compression. Second, since it uses smaller transformer models to learn the compression objective, it has a significantly lower latency. And third, it has been designed to remain faithful to the original prompt and avoid hallucinations.
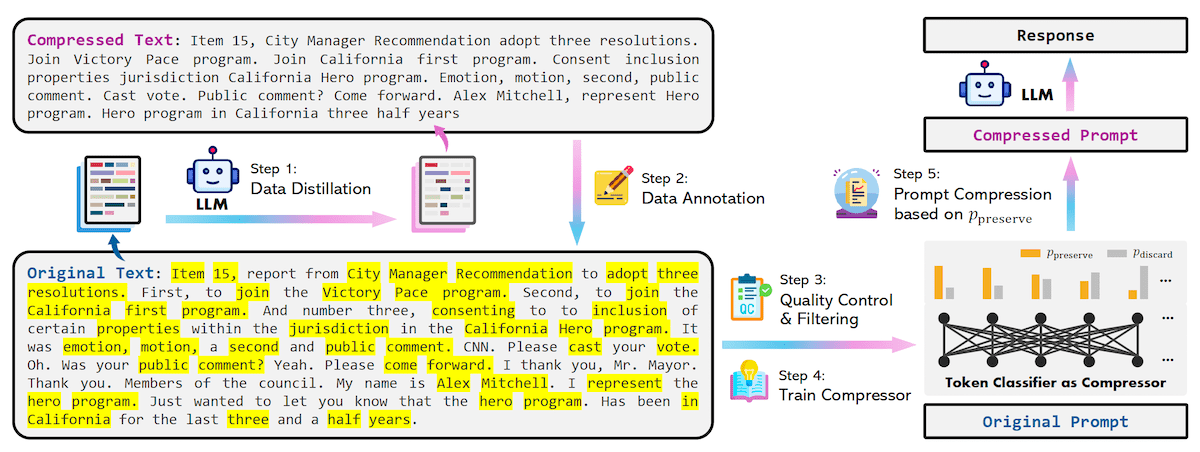
Training the compression model
To generate the dataset for training the prompt compression model, the researchers used a data distillation procedure to extract knowledge from a strong LLM. They provide GPT-4 with a prompt and instruct it to reduce the tokens while preserving essential information and avoiding hallucinations.
After obtaining the pairs of original texts and their compressed versions, they assign a binary label to each token in the original texts to determine if it should be preserved or discarded after compression. The researchers created training examples by using the MeetingBank dataset.
They then trained a slightly modified version of xlm-roberta-large and multilingual-BERT transformer models on the dataset to classify tokens as “preserve” or “discard.” The advantage of BERT-based models is that they learn bidirectional features as opposed to the auto-regressive decoder models that only have knowledge of previous tokens. This allows the compression models to learn richer correlations that can lead to better compression.
“During inference, we determine whether to preserve or discard each token in the original prompt based on its probability calculated by our classification model,” the researchers write.
You can find the source code for LLMLingua-2 on GitHub.

LLMLingua-2 in action
The researchers tested the compression model on both the MeetingBank dataset as well as several out-of-domain datasets such as LongBench, ZeroScrolls, GSM8K, and Big Bench Hard. They used GPT-3.5-Turbo as the target model. But the compression model can also be used with frontier models such as GPT-4 and Claude 3. They compared LLMLingua-2’s compression, speed, and accuracy against other methods as well as the original prompt.
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
Their findings show that despite its small size, LLMLingua-2 compression outperforms other task-agnostic baselines and generalizes well from GPT-3.5-Turbo to Mistral-7B.
LLM-Lingua-2 achieves 2-5x compression ratios and is 3-6x faster than existing prompt compression methods. This means that it can result in massive cost savings when used in applications that require long system and context prompts. LLMLingua-2 also reduces latency by 1.6-2.9x and can reduce GPU memory costs by a factor of 8.
Interestingly, when used with Mistral-7B as the target LLM, the researchers found that LLMLingua-2 yields even better performance than the original prompt. “We speculate that Mistral-7B might be less adept at managing long contexts than GPT-3.5-Turbo. Our method, by offering shorter prompts with higher information density, effectively improves Mistral-7B’s final inference performance,” the researchers write in the paper.
“LLMLingua-2 is a task-agnostic prompt compression method,” Wu said. “This means that whenever you’re dealing with an overly lengthy context, you can use LLMLingua-2 to compress it into a shorter one to accommodate the limited context window, reduce financial costs (as OpenAI charges users by tokens), and decrease the inference time of LLMs.”
However, LLMLingua-2 falls short on specific tasks compared to task-aware compression methods like LongLLMlingua.
“We attribute this performance gap to the additional information that [task-aware methods] leverage from the question,” the researchers write. “However, the task-agnostic characteristics of our model make it an efficient option with good generalizability when deployed across different scenarios.”